Breakthrough AI learns language with “human-like” efficiency

ChatGPT has transformed the way the world talks about (and with) artificial intelligence. Built with OpenAI’s large-language model AI, the chatbot excels at creating human-like responses to all manner of requests — from editing code to suggesting medical diagnoses.
But as impressive as the technology is, in some ways, ChatGPT is less capable than a four-year-old.
One such way is learning efficiency. Consider the concept of apple. A four-year-old will rapidly grasp the concept after encountering a dozen or so examples and, once learned, effortlessly mix it into a variety of situations. She can combine it to form new concepts, such as “apple juice” or “apple cake.” She can grasp the difference between “rolling an apple downhill” and “tossing an apple up high.” And she can discern a picture of an apple, whether a crude drawing or a high-resolution photo.
This may not seem impressive, but for neural network AIs, it’s a tremendous ask. Today’s AIs struggle to learn new concepts and must be trained on many, many examples. That number will vary depending on the model, the concept, and the desired level of accuracy. It might be 100, 1,000, 10,000, or more. They have similar difficulty integrating concepts into fresh contexts and instead mimic pre-existing patterns derived from massive datasets (datasets, it should be noted, that have been helpfully sorted, labeled, and processed by humans).
If four-year-olds required that level of hand-holding, it would take them all of preschool to come to terms with apple. Comparing apples to oranges? Maybe in middle school.
However, researchers are taking a page from how four-year-olds learn, with interesting effects. Brenden Lake, a cognitive computational scientist at New York University, and Marco Baroni, a research professor at Pompeu Fabra University, wanted to see if a neural network could learn language in a human-like manner. And they managed to get closer with something called “meta-learning for compositionality.”
Meta-learning a thing or two
Systematic generalization is our ability to learn new concepts and combine them with existing ones. We saw how four-year-olds do this with apple, but people can do this with pretty much anything they learn. Again, we do this effortlessly and without the need to train on large amounts of preexisting examples.
Just think about all the new concepts added to the dictionary every year. Anyone born before 2000 didn’t grow up knowing what a selfie or photobomb was. But once they learned the concept, they could combine them in fresh contexts: “That seagull photobombed my selfie twice now.”
It doesn’t have to be words either. For example, we learn procedures and strategies for games like Sudoku and chess. Both can be applied to future play or even whole new games that share similar mechanics.
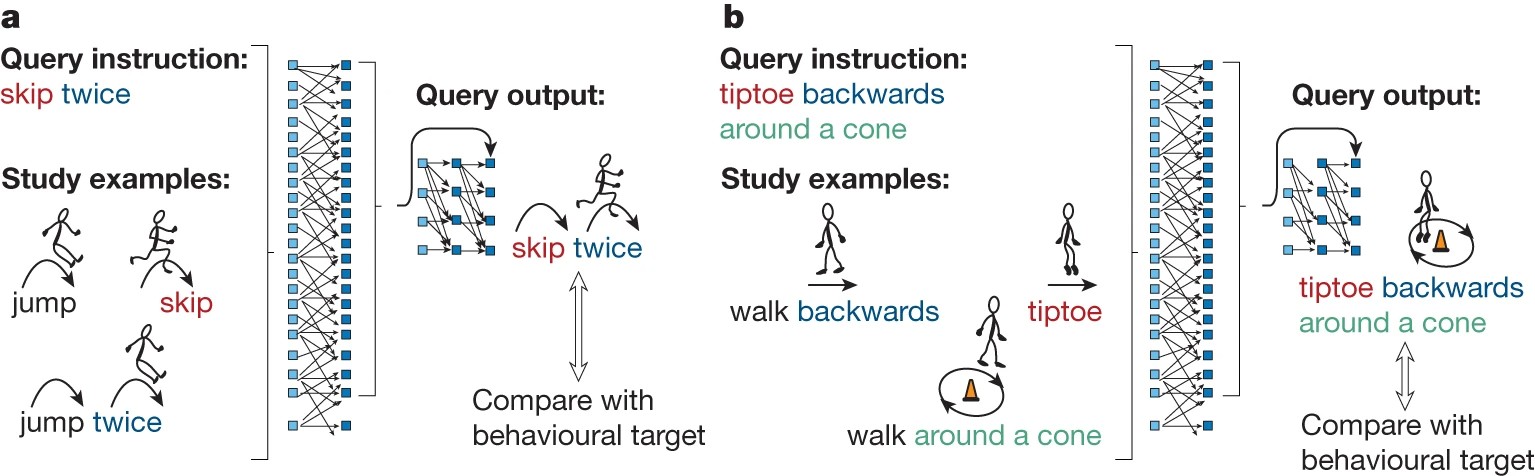
To train their AI to systematically generalize, Lake and Baroni first introduced it to basic concepts — things like hop, skip, and jump. The concepts would be presented as both words and pictures. They would then combine some of those concepts with functional rules like twice. So, jump would become “jump twice” and hop “hop twice.” Other concepts would be left isolated (skip).
They would then ask the neural network to compose a novel combination like “skip twice.” Remember: The AI has never been previously introduced to “skip twice” so it needs to recall what it learned from the other combinations and generalize to the right response.
After practicing on thousands of similar tasks, the AI came to learn from its mistakes. Further learning was reinforced by validating its results against human successes and patterns of error. Hence the name “meta-learning compositionality” — the AI learned how to learn to craft new compositions.
“It’s not magic; it’s practice,” Lake says. “Much like a child also gets practice when learning their native language, the models improve their compositional skills through a series of compositional learning tasks.”
Much like a child also gets practice when learning their native language, the models improve their compositional skills through a series of compositional learning tasks.
Brenden Lake
Do you know your fep from your blicket?
To test their system, Lake and Baroni pitted it against human learners and seven different AI models. However, they couldn’t rely on pre-existing words because they needed to ensure the concepts were truly novel to both the AIs and humans. So, they devised a pseudo-language that used nonsensical words to test how well the humans and machines could learn and use new concepts.
The first category of words was associated with colored circles. Dax represented a red circle, lug represented a blue one, and so on. These served as the test’s basic concepts.
The second category of words was functional, setting rules for arranging the circles. For example, fep may mean “repeat the color three times,” so the proper composition for dax fep would be to arrange three red circles in a row. Similarly, blicket may mean “put the color circle that follows between two of the preceding color,” so the proper response to dax blicket lug would be to arrange the circles in the pattern red-blue-red. (To further ensure the concepts stayed fresh, the nonsense words and their associated concepts were changed with each test.)
After introducing the humans to a few examples — such as showing them dax fep next to three red circles — the researchers tested them on more challenging combinations. “To perform well,” Lake and Baroni write, “the participants would need to learn the meaning of the words from just a few examples and generalize to more complex instructions.”
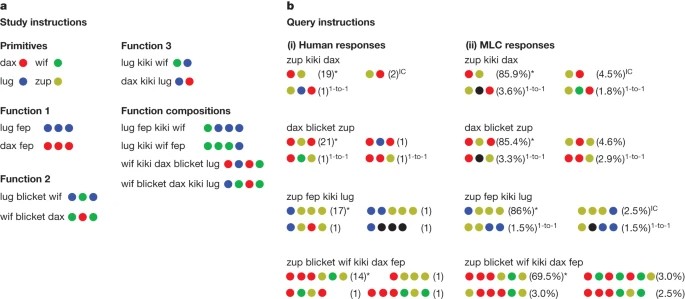
And they did. The 25 human participants chose the correct colored circles and ordered them properly about 80% of the time. Even when the humans got the answer wrong, the researchers noted, it wasn’t a random flub but the kind of error one would expect given our cognitive biases.
Lake and Baroni’s AI’s performance was on par with the humans. In fact, it occasionally edged them out in correct responses while also making similar reasoning errors.
However, the other models tested didn’t fare so well. Under certain settings, ChatGPT-4 could perform reasonably well — sometimes as high as 58%. However, the researchers found that even minor differences in word order or requested combination could dramatically drop its performance. That’s because rather than learning how to perform the task, ChatGPT was relying on patterns in its original training data (which obviously didn’t include any feps or blickets).
Lake and Baroni published their study in the peer-reviewed journal Nature.
Teaching AI new tricks
With that said, AIs still have a ways to go to develop human-like learning efficiency. In the study, Lake and Baroni point out that their AI can’t automatically handle unpracticed forms of generalization, and it remains untested on the complexity of natural language. As such, the current study is more of a proof of concept.
Lake hopes to improve their neural net by studying how young people develop systematic generalization and then incorporate those findings. If he and Baroni can do so, it could potentially lead to more human-like AI. It may also make them easier to develop as they wouldn’t require such massive datasets and be less prone to “hallucinate” (when an AI outputs a pattern that is either nonsensical or not factual).
“Infusing systematicity into neural networks is a big deal,” Elia Bruni, a professor of natural language processing at the University of Osnabrück, said.
Until then, however, human four-year-olds will keep their seats at the head of the class.





